
Le machine learning, ou apprentissage automatique ou statistique en français, cet article wikipédia nous dit que cela "concerne la conception, l'analyse, le développement et l'implémentation de méthodes permettant à une machine (au sens large) d'évoluer par un processus systématique, et ainsi de remplir des tâches difficiles ou impossibles à remplir par des moyens algorithmiques plus classiques."
Avant tout, je précise que je ne suis pas un spécialiste du domaine.
En se basant sur des exemples issus d'une série de vidéos de Google Developers, nous allons voir à quoi cela correspond plus concrètement. Pour cela nous utiliseront Scikit-learn et TensorFlow, des bibliothèques python libres d'apprentissage automatique.
- Classification d'éléments par caractéristiques
Il s'agit d'être capable de classifier des éléments à partir d'un jeu de données contenant des caractéristiques.
Dans cet exemple, nous allons tenter de classifier des iris dans leur sous-espèce à partir de la longueur et de la largeur des sépales et des pétales. Pour cela nous disposons du tableau suivant contenant 150 entrées (disponible dans son intégralité sur cet article wikipédia) :
| longueur des sépales | largeur des sépales | longueur des pétales | largeur des pétales | espèce |
| 5,1 | 3,5 | 1,4 | 0,2 | setosa |
| 4,9 | 3 | 1,4 | 0,2 | setosa |
| 4,7 | 3,2 | 1,3 | 0,2 | setosa |
| 4,6 | 3,1 | 1,5 | 0,2 | setosa |
| 5 | 3,6 | 1,4 | 0,2 | setosa |
| 5,4 | 3,9 | 1,7 | 0,4 | setosa |
| 4,6 | 3,4 | 1,5 | 0,2 | setosa |
| [...] | ||||
| 7 | 3,2 | 4,7 | 1,4 | versicolor |
| 6,4 | 3,2 | 4,5 | 1,5 | versicolor |
| 6,9 | 3,1 | 4,9 | 1,5 | versicolor |
| 5,5 | 2,3 | 4 | 1,3 | versicolor |
| 6,5 | 2,8 | 4,6 | 1,5 | versicolor |
| 5,7 | 2,8 | 4,5 | 1,3 | versicolor |
| [...] | ||||
| 6,3 | 3,3 | 6 | 2,5 | virginica |
| 5,8 | 2,7 | 5,1 | 1,9 | virginica |
| 7.1 | 3 | 5,9 | 2,1 | virginica |
| 6.3 | 2,9 | 5,6 | 1,8 | virginica |
| 6.5 | 3 | 5,8 | 2,2 | virginica |
| 7.6 | 3 | 6,6 | 2,1 | virginica |
| [...] | ||||
Le code suivant utilise une méthode générant un arbre de décision. Il résout le problème en quelques lignes :
import numpy as np
from sklearn.datasets import load_iris
from sklearn import tree
# (1)
# import des donnees
iris = load_iris()
# (2)
test_idx = [0, 50, 100]
# donnees entrainement
train_target = np.delete(iris.target, test_idx)
train_data = np.delete(iris.data, test_idx, axis=0)
# donnees test
test_target = iris.target[test_idx]
test_data = iris.data[test_idx]
# (3)
# entrainement
clf = tree.DecisionTreeClassifier()
clf = clf.fit(train_data, train_target)
# (4)
txt_result =['setosa', 'versicolor', 'virginica']
# calcul et affichage des resulats
result = clf.predict(test_data)
for i in range(len(result)):
print str(test_data[i]) + " --> ",
print txt_result[result[i]]
Dans l'ordre, on effectue les opérations suivantes :
- Importer toutes les données
- Exclure la première setosa (idx 0), la première versicolor (idx 50) et la première virginica (idx 100) des données d'entrainement, pour les utiliser comme données de test
- L'algorithme créé un arbre de décision
- Calculer et afficher les résultats pour les données de test
A l'exécution du script, on remarque que l'arbre de décision créé par l'algorithme, permet effectivement de catégoriser l'espèce :
$ python arbre_iris.py
[ 5.1 3.5 1.4 0.2] --> setosa
[ 7. 3.2 4.7 1.4] --> versicolor
[ 6.3 3.3 6. 2.5] --> virginica
Avec un peu plus de code, de manière à visualiser son fonctionnement, on peut générer une image représentant l'arbre de décision qui a été créé par l'algorithme :
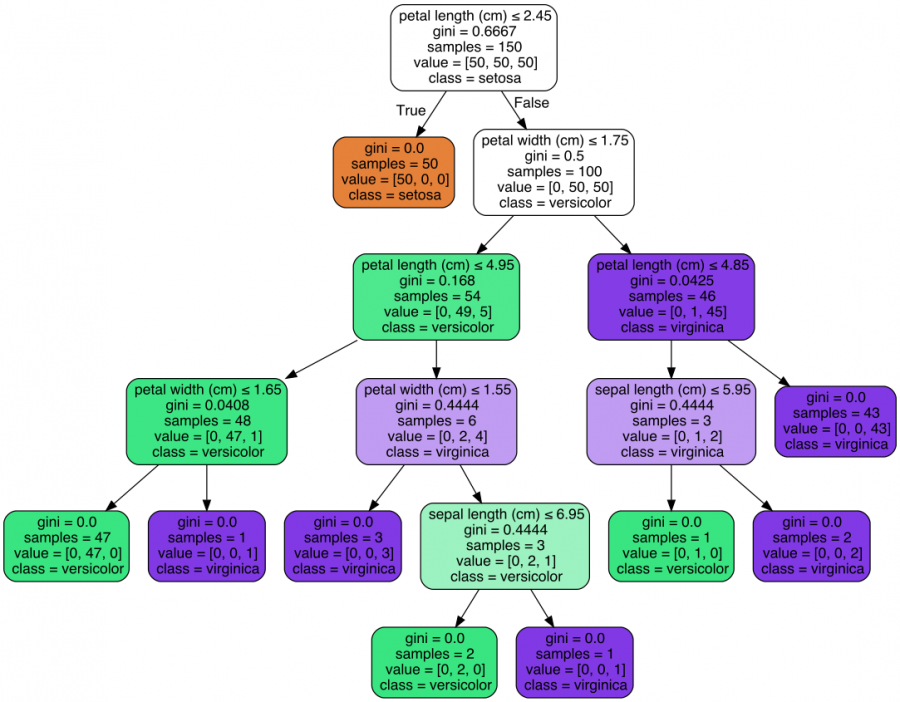
On peut aussi utiliser la méthode des k plus proches voisins. Pour cela il suffit de changer deux lignes dans le code précédent :
import numpy as np
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier # <--------------- ligne changee
# import des donnees
iris = load_iris()
test_idx = [0, 50, 100]
# donnees entrainement
train_target = np.delete(iris.target, test_idx)
train_data = np.delete(iris.data, test_idx, axis=0)
# donnees test
test_target = iris.target[test_idx]
test_data = iris.data[test_idx]
# entrainement
clf = KNeighborsClassifier() # <--------------- ligne changee
clf = clf.fit(train_data, train_target)
txt_result =['setosa', 'versicolor', 'virginica']
# calcul et affichage des resulats
result = clf.predict(test_data)
for i in range(len(result)):
print str(test_data[i]) + " --> ",
print txt_result[result[i]]
À l'exécution du script, on obtient les mêmes résultats qu'auparavant, l'algorithme catégorise bien l'espèce :
$ python arbre_iris.py
[ 5.1 3.5 1.4 0.2] --> setosa
[ 7. 3.2 4.7 1.4] --> versicolor
[ 6.3 3.3 6. 2.5] --> virginica
On constate donc qu'avec une quinzaine de ligne de code, il est assez simple de classifier des éléments à partir d'un jeu de données contenant des caractéristiques numériques.
- Classification d'images
Il s'agit d'être capable de classifier des images, en entrainant un algorithme avec d'images connues.
Dans cet exemple, nous allons tenter de différencier et catégoriser des images de roses et de tulipes. Pour cela nous utiliserons inception, un réseau pré-entrainé développé par Google. Pour terminer son entrainement, nous lui fournirons 641 images de roses et 799 images de tulipes, dont voici un échantillon :
On commence par terminer l'entrainement de l'algorithme avec la commande suivante :
$ python retrain.py \
--bottleneck_dir=/bottlenecks \
--model_dir=/inception \
--output_graph=/retrained_graph.pb \
--output_labels=/retrained_labels.txt \
--image_dir /img
Elle prend un certain temps et affiche les éléments suivants :
Looking for images in 'roses'
Looking for images in 'tulipes'
Creating bottleneck at /bottlenecks/roses/9433167170_fa056d3175.jpg.txt
Creating bottleneck at /bottlenecks/roses/9458445402_79e4dfa89c.jpg.txt
[...]
Creating bottleneck at /bottlenecks/tulipes/8712263493_3db76c5f82.jpg.txt
Creating bottleneck at /bottlenecks/tulipes/8712266605_3787e346cd_n.jpg.txt
[...]
2016-12-25 18:46:40.000000: Step 0: Train accuracy = 59.0%
2016-12-25 18:46:40.236750: Step 0: Cross entropy = 0.643191
2016-12-25 18:46:40.583488: Step 0: Validation accuracy = 50.0%
2016-12-25 18:46:43.671932: Step 10: Train accuracy = 81.0%
2016-12-25 18:46:43.672876: Step 10: Cross entropy = 0.514823
2016-12-25 18:46:44.015942: Step 10: Validation accuracy = 87.0%
[...]
2016-12-25 19:04:52.943261: Step 3999: Train accuracy = 98.0%
2016-12-25 19:04:52.944066: Step 3999: Cross entropy = 0.088042
2016-12-25 19:04:53.190913: Step 3999: Validation accuracy = 85.0%
Final test accuracy = 93.0%
Converted 2 variables to const ops.
Après qu'il a analysé les 1440 images, nous obtenons deux fichiers : "retrained_graph.pb" et "retrained_labels.txt". À partir de ces deux fichiers, nous pouvons tenter d'identifier des images en utilisant le code suivant :
import tensorflow as tf, sys
image_path = sys.argv[1]
# Read in the image_data
image_data = tf.gfile.FastGFile(image_path, 'rb').read()
# Loads label file, strips off carriage return
label_lines = [line.rstrip() for line in tf.gfile.GFile("./retrained_labels.txt")]
# Unpersists graph from file
with tf.gfile.FastGFile("./retrained_graph.pb", 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(graph_def, name='')
with tf.Session() as sess:
# Feed the image_data as input to the graph and get first prediction
softmax_tensor = sess.graph.get_tensor_by_name('final_result:0')
predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data})
# Sort to show labels of first prediction in order of confidence
top_k = predictions[0].argsort()[-len(predictions[0]):][::-1]
for node_id in top_k:
human_string = label_lines[node_id]
score = predictions[0][node_id]
print('%s (score = %.5f)' % (human_string, score))
Il suffit ensuite de lui passer une image en argument et il l'identifie lorsque c'est possible :
$ python label_image.py rose.jpg
roses (score = 0.99040)
tulipes (score = 0.00960)
$ python label_image.py tulipe.jpg
tulipes (score = 0.99649)
roses (score = 0.00351)
$ python label_image.py marguerite.jpg
roses (score = 0.66204
tulipes (score = 0.33796)
On constate que, lorsqu'on lui fournit une image de rose, il l'identifie à 99 %. Il en est de même pour la tulipe. Lorsqu'on lui fournit une image contenant une marguerite, un type d'image pour lequel l'algorithme n'a pas été entrainé, il tente tout de même de l'identifier comme une rose ou une tulipe. Mais les indices de confiance sont beaucoup moins tranchés et on peut conclure qu'il ne s'agit ni d'une rose, ni d'une tulipe.
Ainsi, de nouveau, une quinzaine de ligne de code permet de classifier des images pour lesquelles l'algorithme a été entrainé.
- Ce que cela implique
Dans le cas du premier exemple, on pourrait étudier les données du tableau et en déduire un arbre de décision, qu'un développeur pourrait transformer en code. Cependant, le nombre de lignes nécessaires serait beaucoup plus important et à chaque nouvelle problématique l'arbre de décision devrait être de nouveau créé et retraduit en code.
C'est là toute la puissance des algorithmes d'apprentissage automatiques, le même code peut être réutilisé pour des problèmes différents.
Dans le cas du second exemple, c'est totalement différent. Il s'agit d'une problématique qu'on ne peut pas résoudre en utilisant des méthodes de développement procédurales classiques. Seuls les réseaux de neurones permettent d'obtenir des résultats fiables.
Comme nous l'avons montré dans les paragraphes précédents, aujourd'hui, des outils libres tels que Scikit-learn ou TensorFlow permettent de mettre en œuvre, sans trop de difficultés, des algorithmes d'apprentissage automatique. De ce fait, il n'est plus nécessaire de disposer d'une grosse équipe de recherche et développement pour pouvoir les implémenter dans les entreprises.
Quand je repense aux quelques fois où j'ai été confronté à des problématiques de classements, que j'ai dû résoudre avec des centaines de lignes de codes, je me dis qu'aujourd'hui je pourrais en venir à bout beaucoup plus simplement et rapidement.