
Dans ses group labs, OVH a lancé prescience, une plateforme de machine learning. C'est gratuit pendant la phase alpha et j'ai donc décidé de tester le future produit.
Il faut demander un accès en bas de la page dédié à prescience et quelque temps après, on reçoit un mail avec le token pour s'identifier sur la pateforme :
J'ai utilisé un des dataset de base pour le machine learning : iris. Il s'agit d'un tableau contenant 150 entrées (disponible dans son intégralité sur cet article wikipédia).
On commence par créer un fichier csv avec les 150 entrées :
sepal_lenght;sepal_width;petal_lenght;petal_width;species
5.1;3.5;1.4;0.2;setosa
4.9;3.0;1.4;0.2;setosa
4.7;3.2;1.3;0.2;setosa
4.6;3.1;1.5;0.2;setosa
[...]
7.0;3.2;4.7;1.4;versicolor
6.4;3.2;4.5;1.5;versicolor
6.9;3.1;4.9;1.5;versicolor
5.5;2.3;4.0;1.3;versicolor
6.5;2.8;4.6;1.5;versicolor
[...]
6.3;3.3;6.0;2.5;virginica
5.8;2.7;5.1;1.9;virginica
7.1;3.0;5.9;2.1;virginica
6.3;2.9;5.6;1.8;virginica
6.5;3.0;5.8;2.2;virginica
[...]
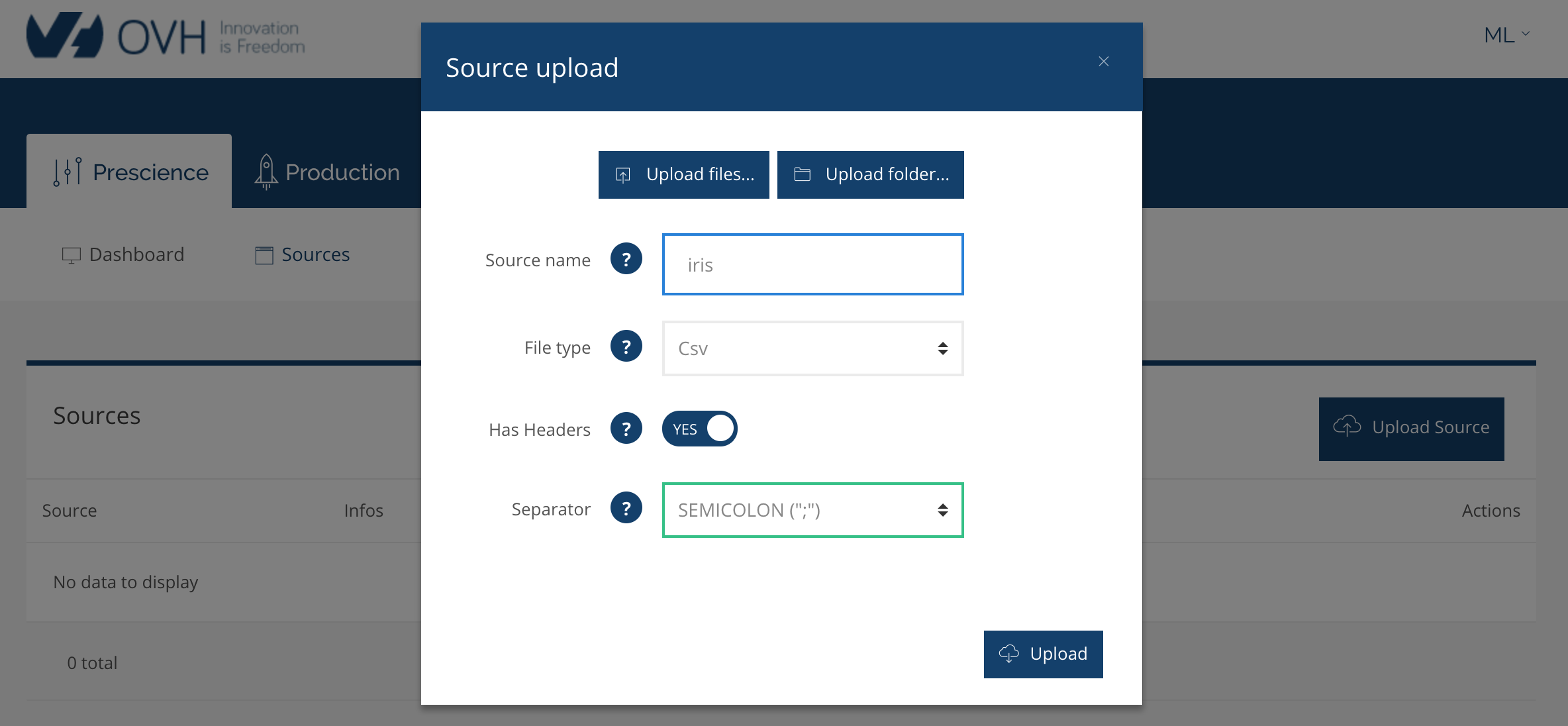
En peut ensuite uploader ce fichier dans prescience :
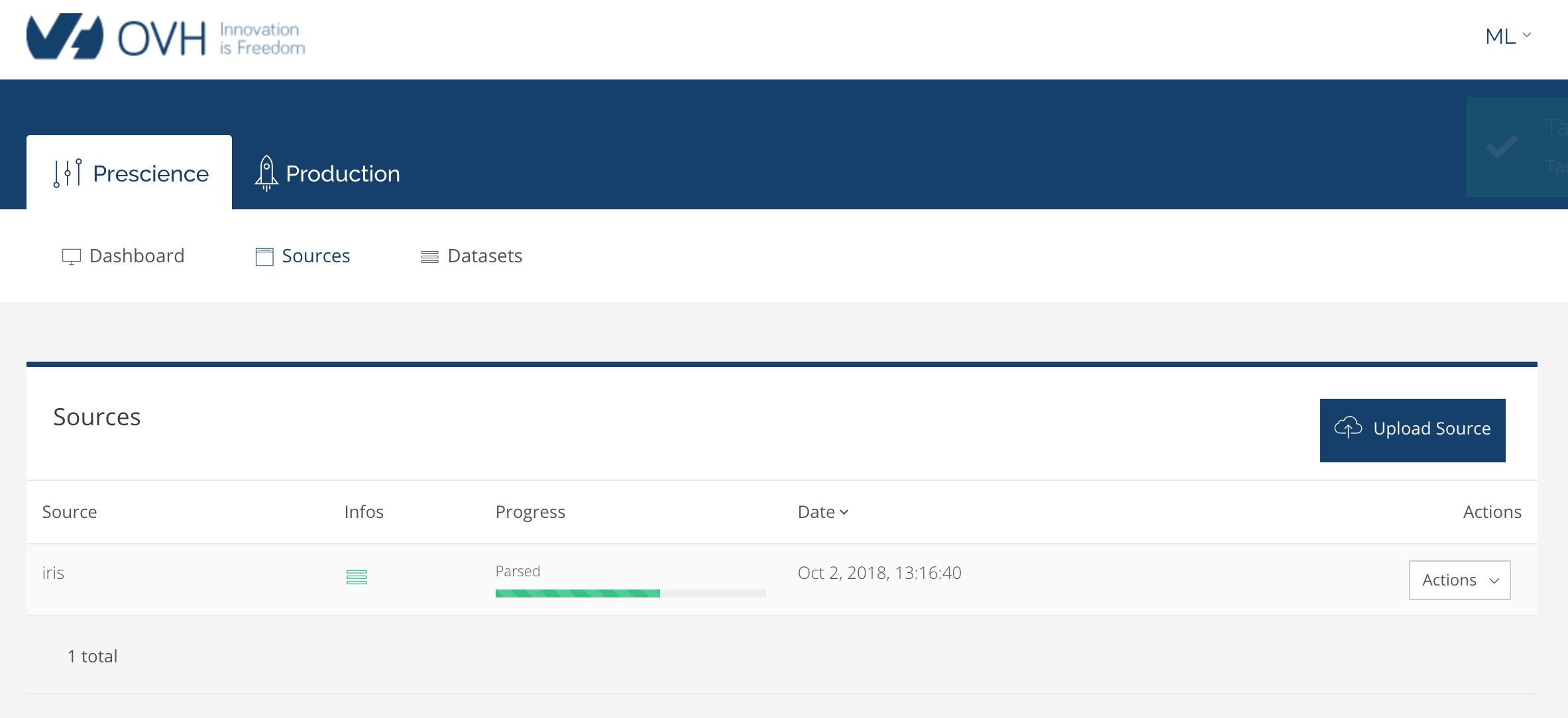
Après avoir cliqué sur upload, le système télécharge le fichier et commence à le parser :
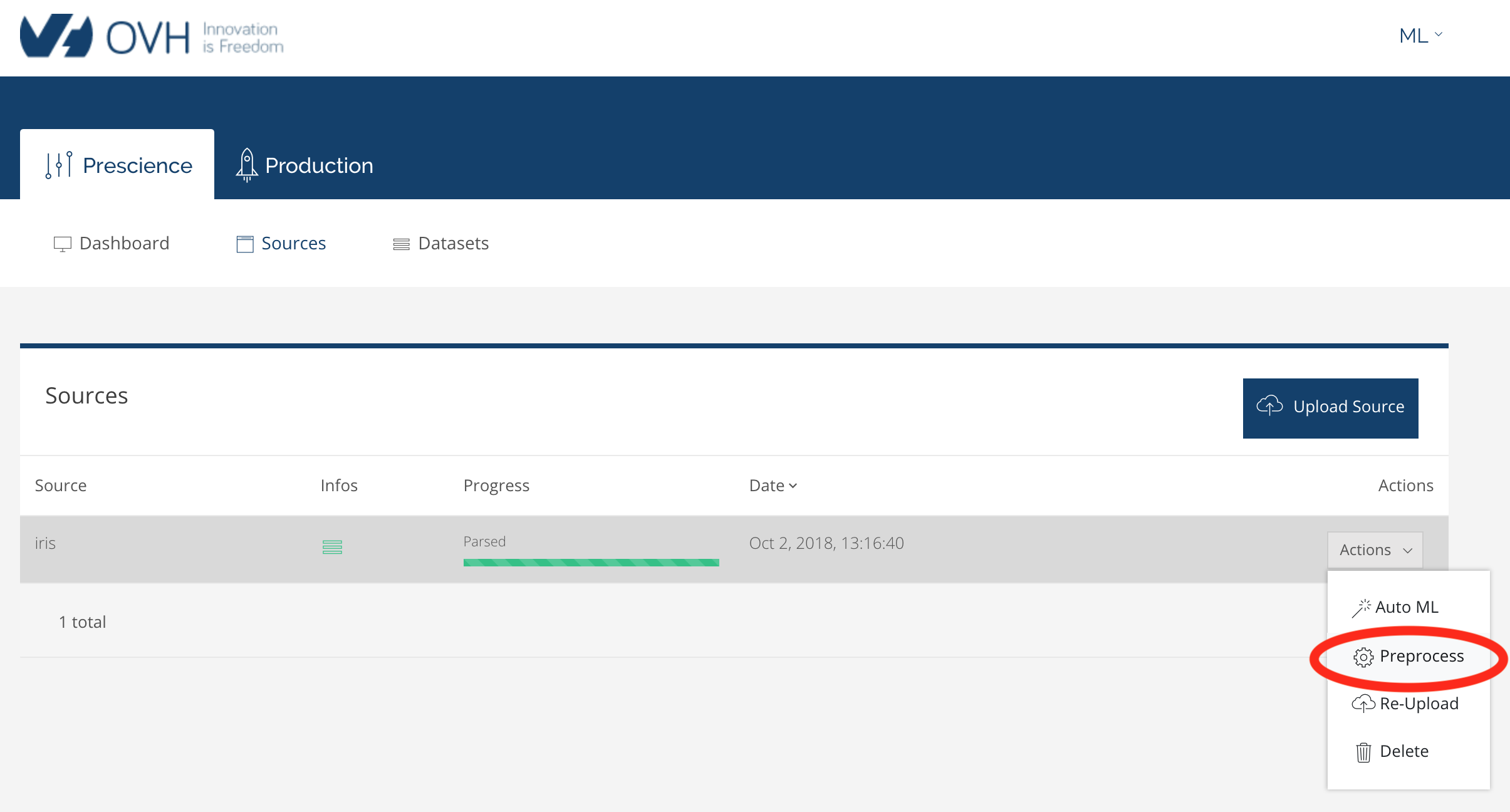
Lorsqu'il a terminé, on peut préprocesser la source :
Le système nous demande alors quelques informations, notamment le label et le type de problème. Dans notre cas, tout est sélectionné automatiquement :
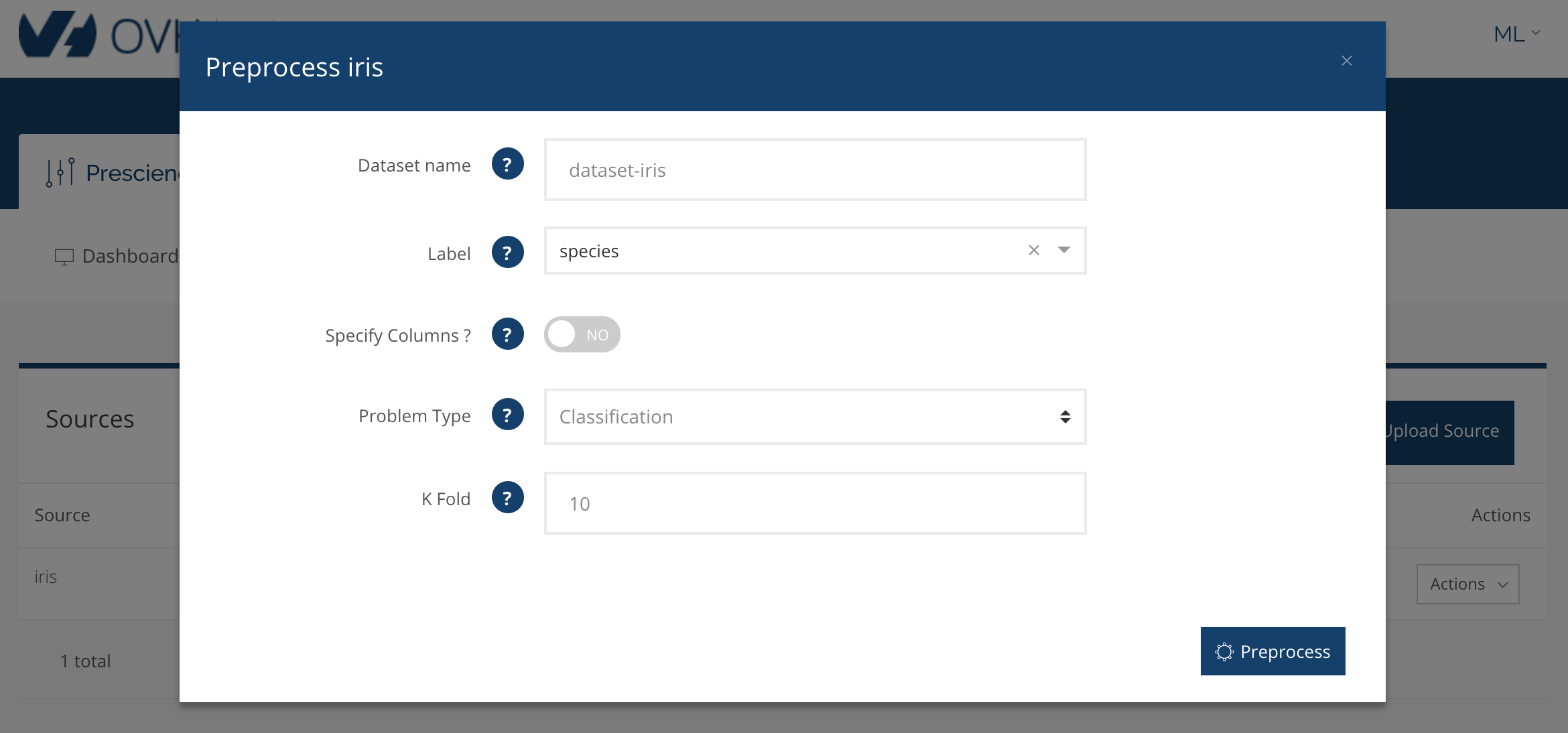
Lorqu'on clique sur sur preprocess, le système lance le préprocessing en quatre étapes :
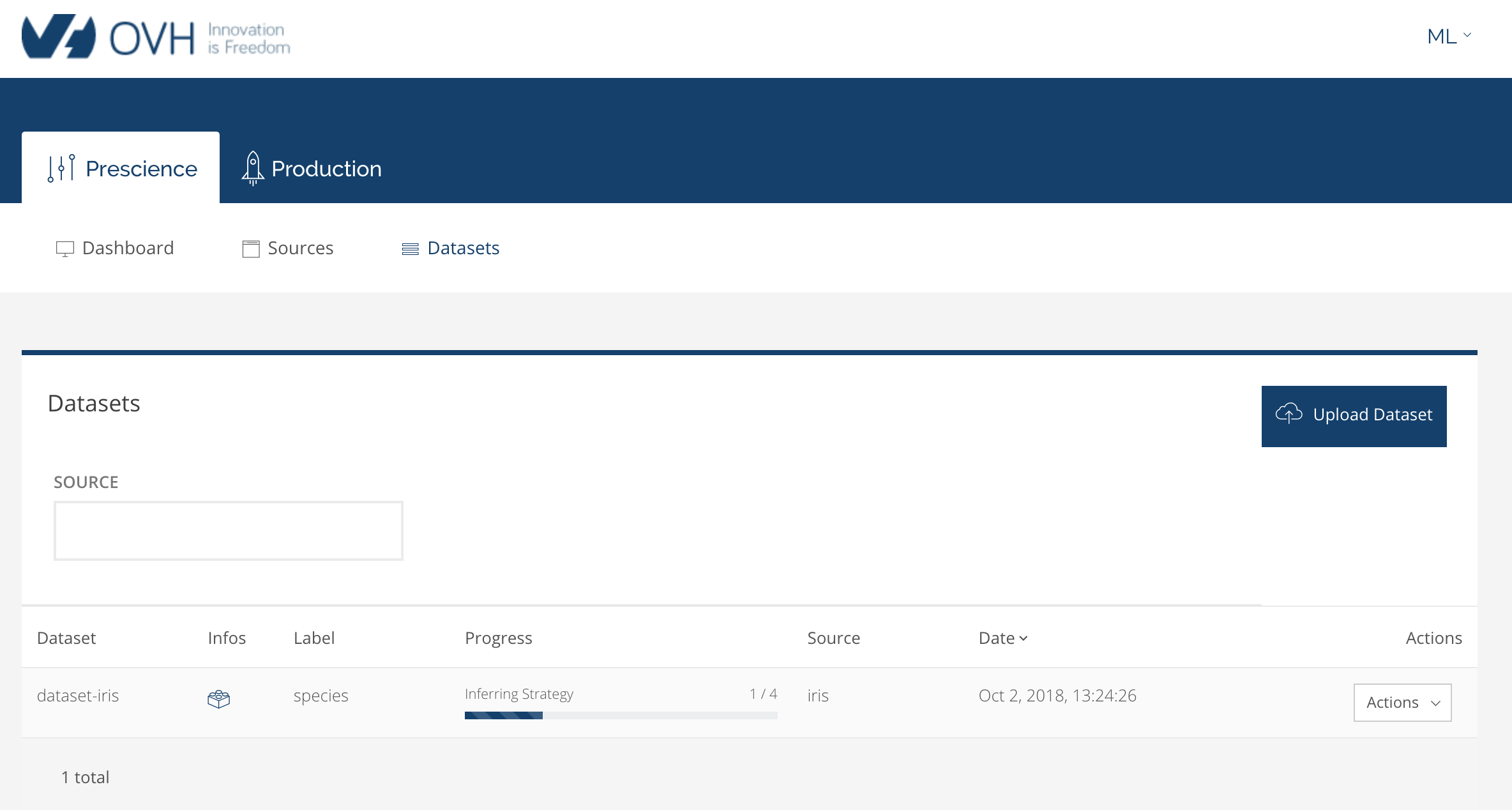
Les deux premières étapes sont plutôt rapides. Les deux suivantes peuvent prendre un peu de temps. Lorsqu'il a terminé le préprocessing, on peut lancer l’optimisation :
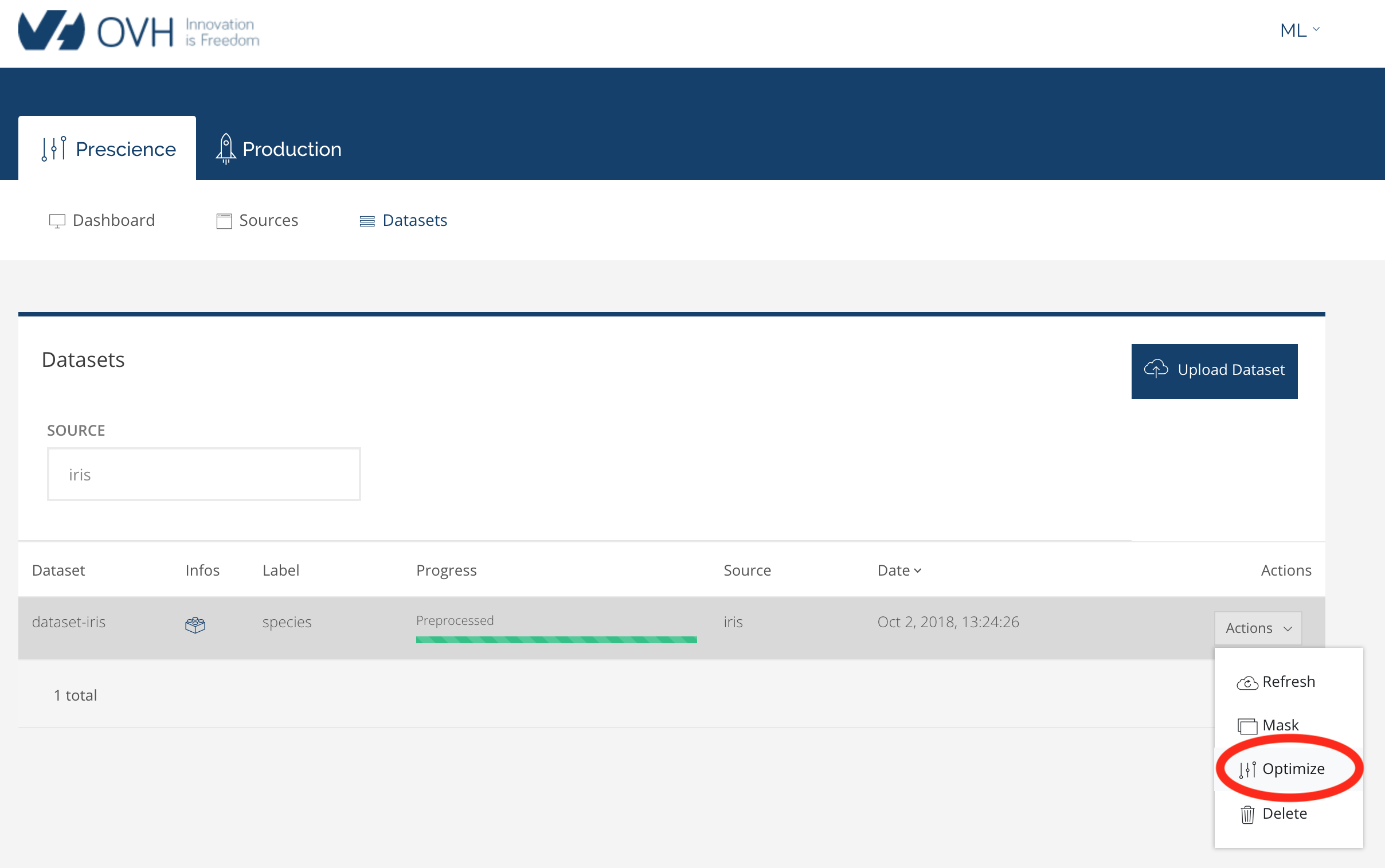
Le système nous demande des paramètres que nous laissons tels quels :
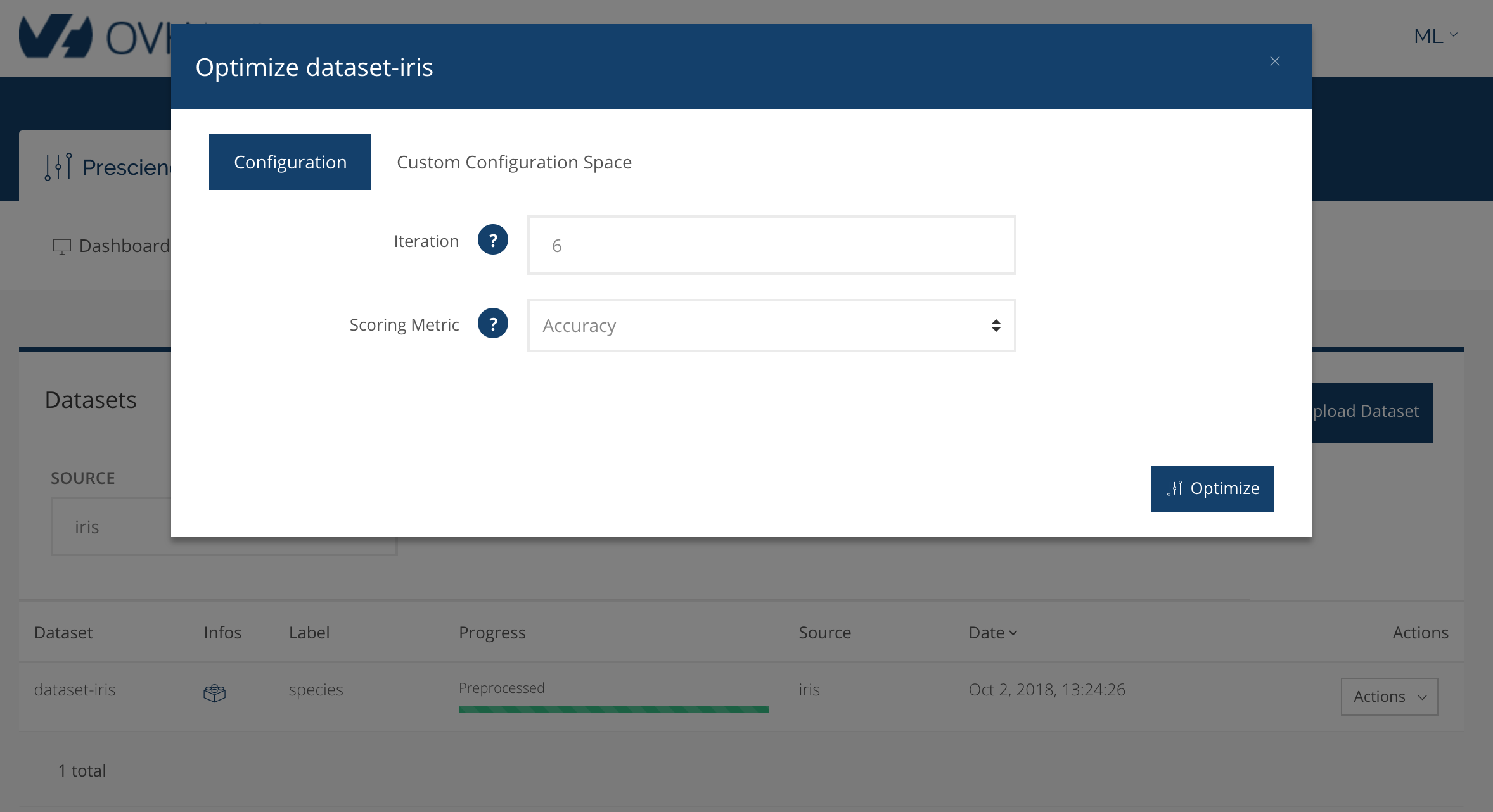
Lorsqu'on clique sur optimise, on obtient quelque chose comme ça :
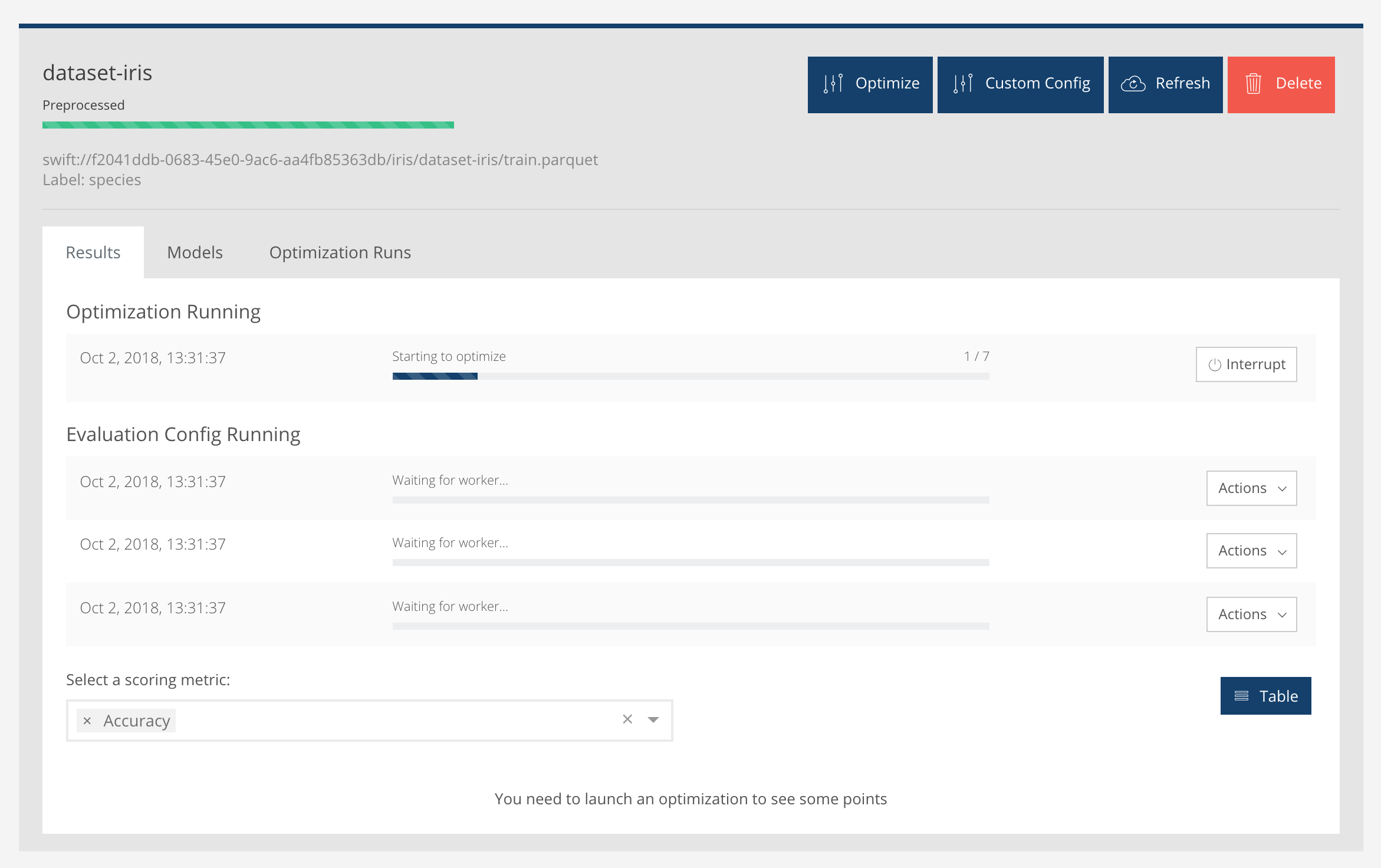
Il faut maintenant le laisser travailler un peu. En effet, cette phase peut prendre du temps. À l'issue, on peut lancer l'entrainement :
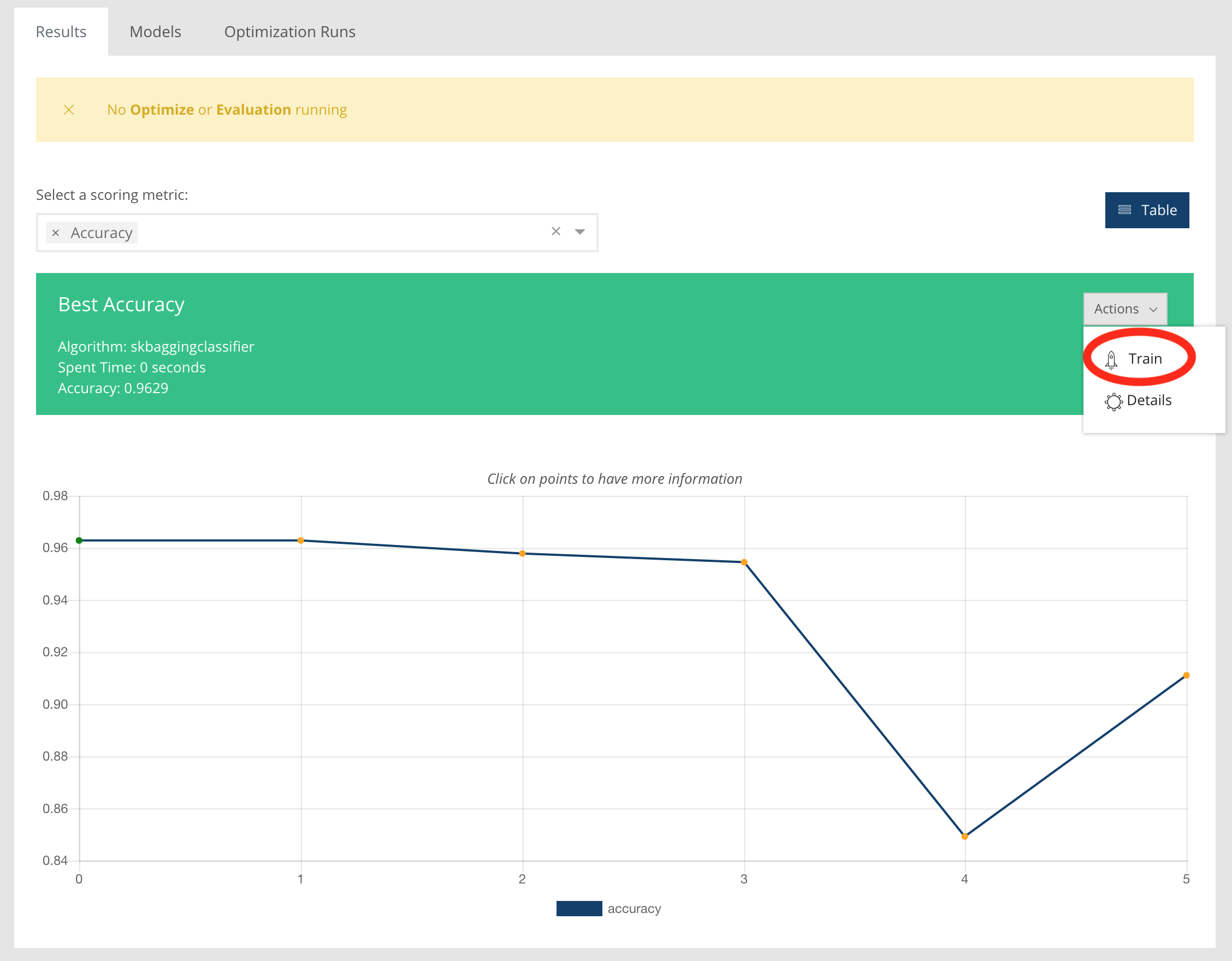
Le système nous demande un nom de modèle :
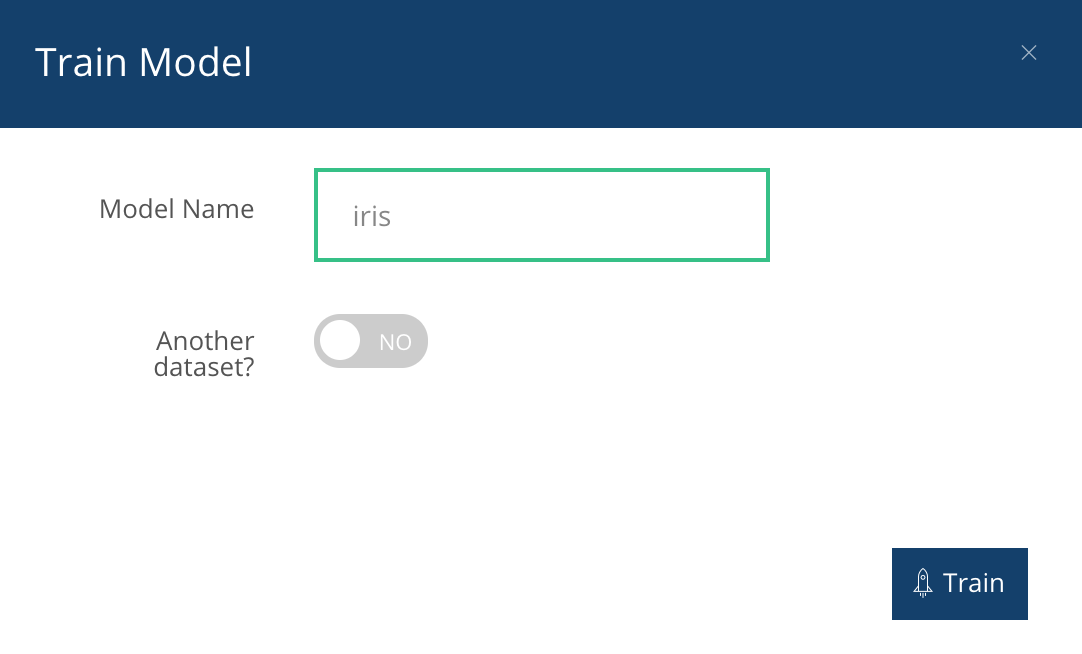
Lorsqu'on clique sur train, on obtient cela :
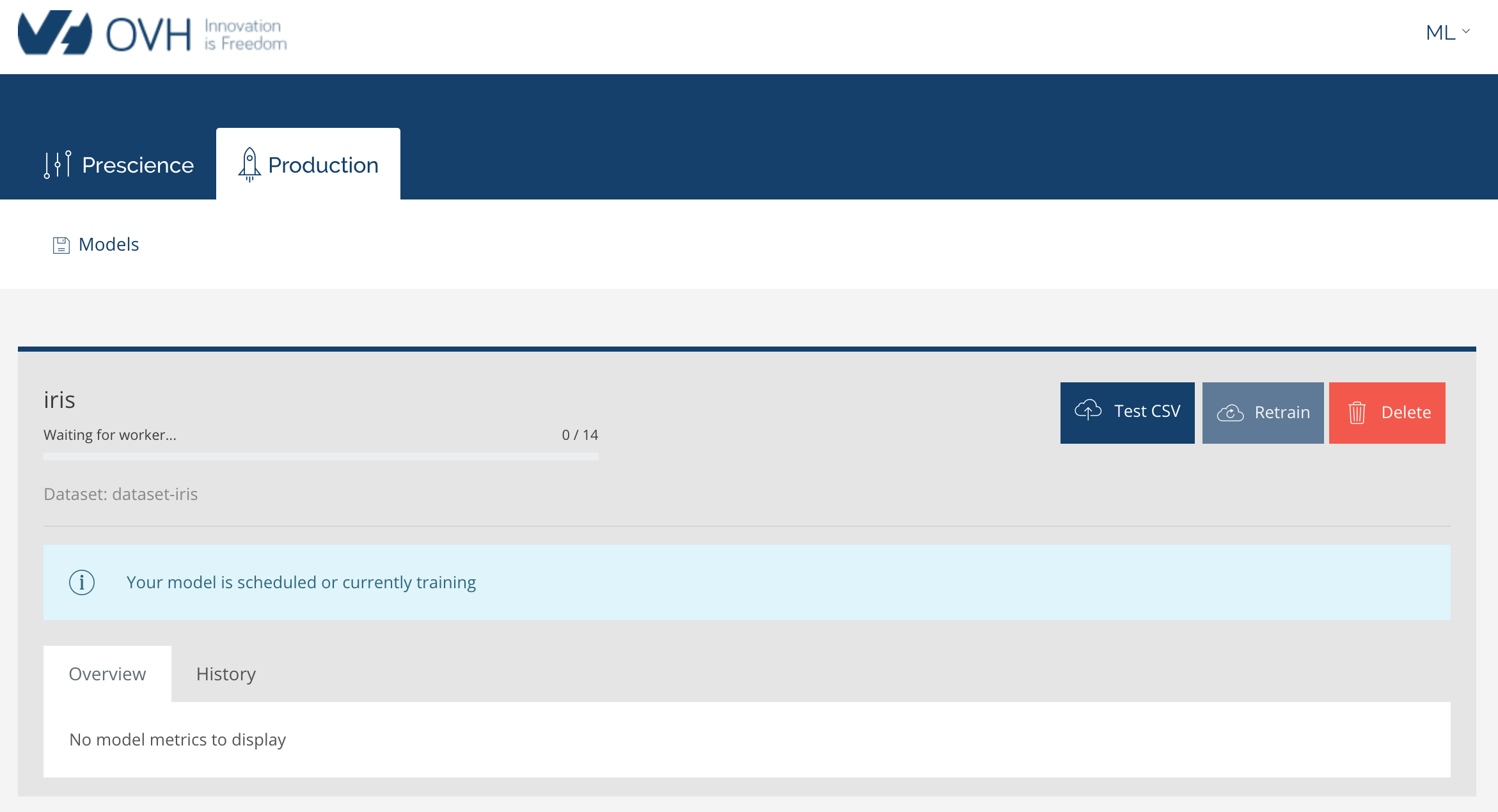
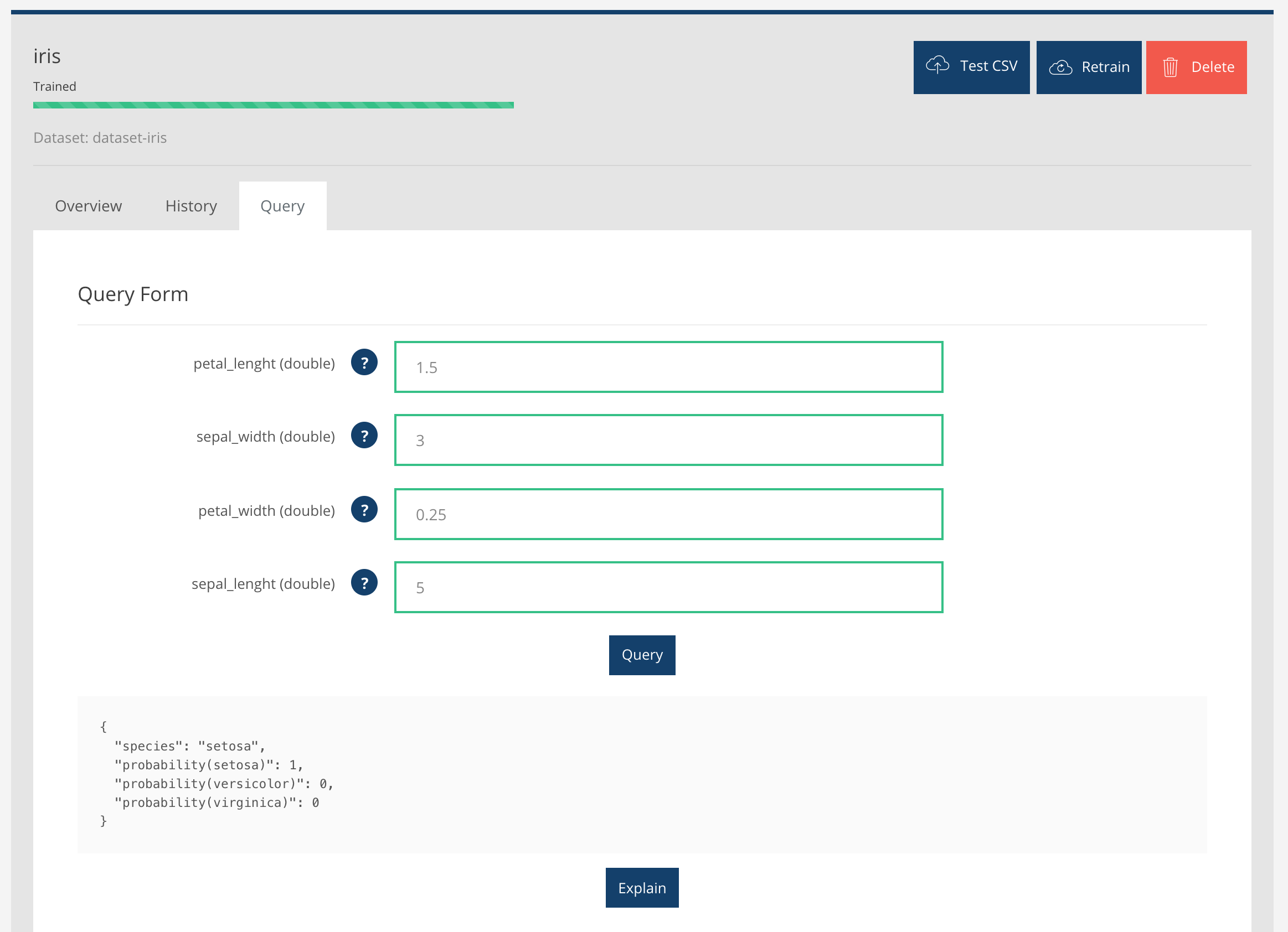
Quand l'entrainement est terminé, on peut interroger le système. Par exemple, si on entre une longueur des pétales de 1.5 cm, une largeur des sépales de 3 cm, une largeur des pétales de 0.25 cm et une largeur des sépales de 5 cm, le système nous indique qu'il s'agit, avec une probabilité de 1, de l'espèce setosa(ce qui est le cas) :
Si on clique sur explain, on obtient le joli graphique suivant :

Enfin, il est possible d'interroger le système avec curl :
$ curl -X POST "https://prescience-serving.ai.ovh.net/eval/iris/transform-model" -H "Authorization: $token" -H "Content-Type: application/json" -d '{"arguments":{"petal_lenght":1.5,"sepal_width":3,"petal_width":0.25,"sepal_lenght":5}}'
{"result":{"species":"setosa","probability(setosa)":1.0,"probability(versicolor)":0.0,"probability(virginica)":0.0},"arguments":{"imputed_petal_lenght":{"dataType":"double","value":1.5,"opType":"continuous"},"imputed_sepal_width":{"dataType":"double","value":3.0,"opType":"continuous"},"imputed_petal_width":{"dataType":"double","value":0.25,"opType":"continuous"},"imputed_sepal_lenght":{"dataType":"double","value":5.0,"opType":"continuous"},"scaled_imputed_petal_lenght":{"dataType":"double","value":-1.2266889625508433,"opType":"continuous"},"scaled_imputed_sepal_width":{"dataType":"double","value":-0.15118917210787064,"opType":"continuous"},"scaled_imputed_petal_width":{"dataType":"double","value":-1.1917094761129958,"opType":"continuous"},"scaled_imputed_sepal_lenght":{"dataType":"double","value":-1.0113190222659707,"opType":"continuous"}}}
C'est un exemple très simple mais cela fonctionne plutôt bien.
Ainsi, si on possède des données, on peut, sans rien connaitre ou comprendre à l'apprentissage automatisé, mettre en œuvre du machine learning en quelques clics.
Merci OVH.