
La semaine dernière, une équipe du CWI et de Google Research a publié le site shattered.io. Ils montrent la première collision SHA1 réelle. Il s'agit de générer deux fichiers différents présentant le même hash, SHA1 dans ce cas. L'objet de cet article est l'analyse en profondeur de ces deux fichiers afin de déterminer comment cela peut fonctionner.
Tout d'abord, ils présentent bien un SHA1 identique, mais un MD5 différent :
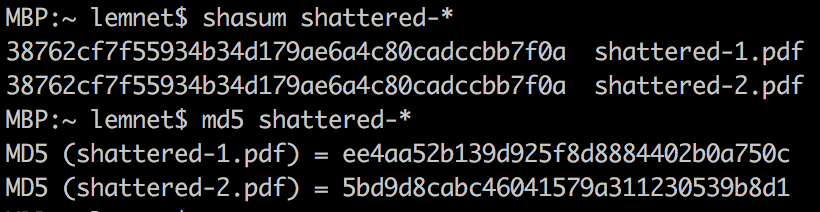
Les MD5 montrent que les fichiers sont bien différents.
Il s'agit de PDF ne contenant qu'une page. Visuellement, on les différencie par la couleur de fond de la partie haute. Sur le premier fichier, elle est bleue et sur le second, elle est rouge.

Les deux fichiers font exactement la même taille. Lorsqu'on les compare, on constate que 99,97 % de leur contenu sont strictement identiques. Seuls 62 octets entre les offset 0xC0 et 0x130 sont différents :
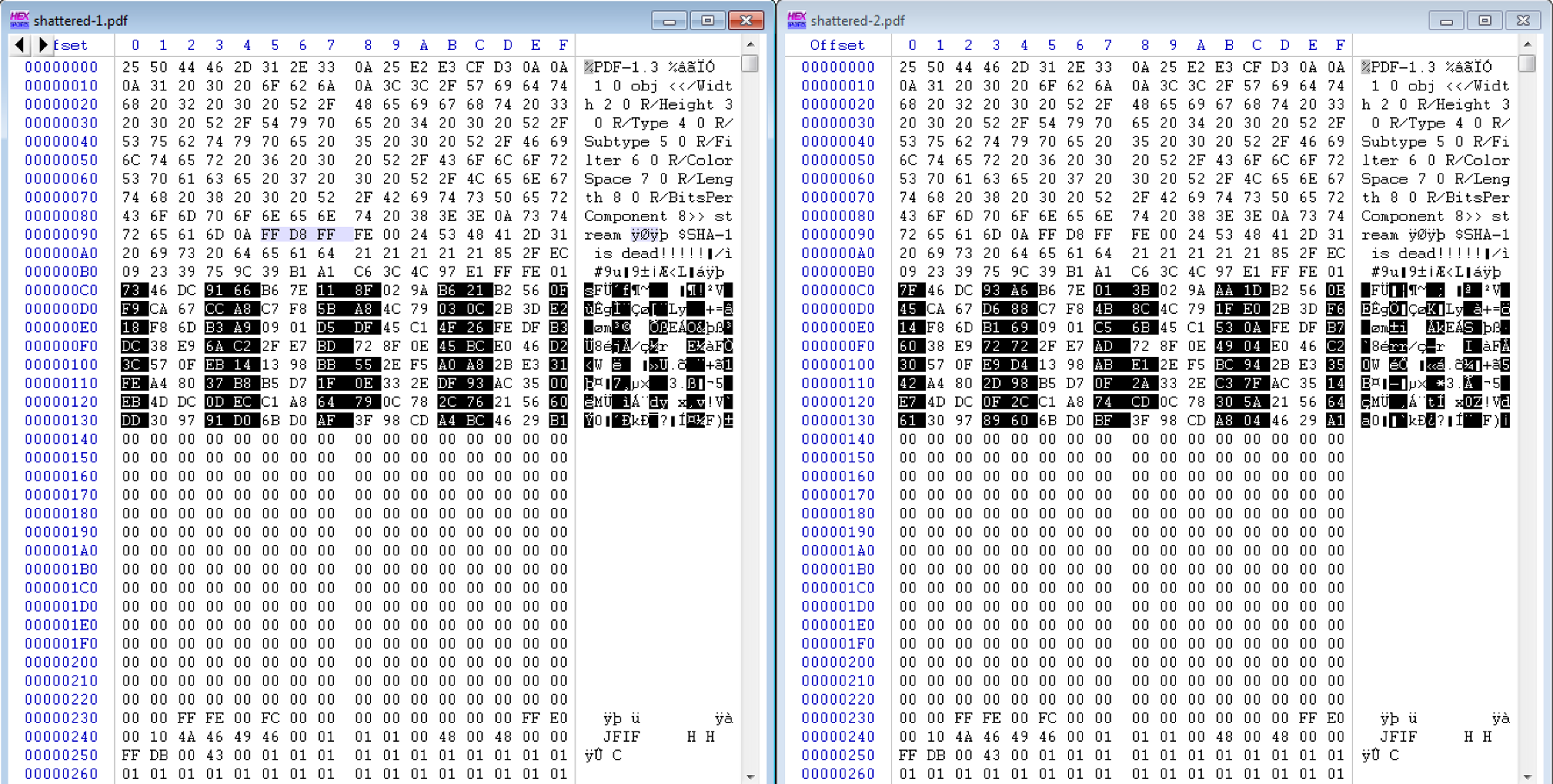
On remarque également que les fichiers PDF contiennent chacun la signature d'un fichier JPG à l'offset 0x95. Ces images occupent, à elles seules, plus de 99 % des PDF. A l'aide de PDF Stream Dumper, on peut visualiser les différents flux des PDF. On constate qu'il n'y en a que 13 et qu'ils sont structurés très simplement. Ce logiciel permet également d'extraire les fichiers JPG :
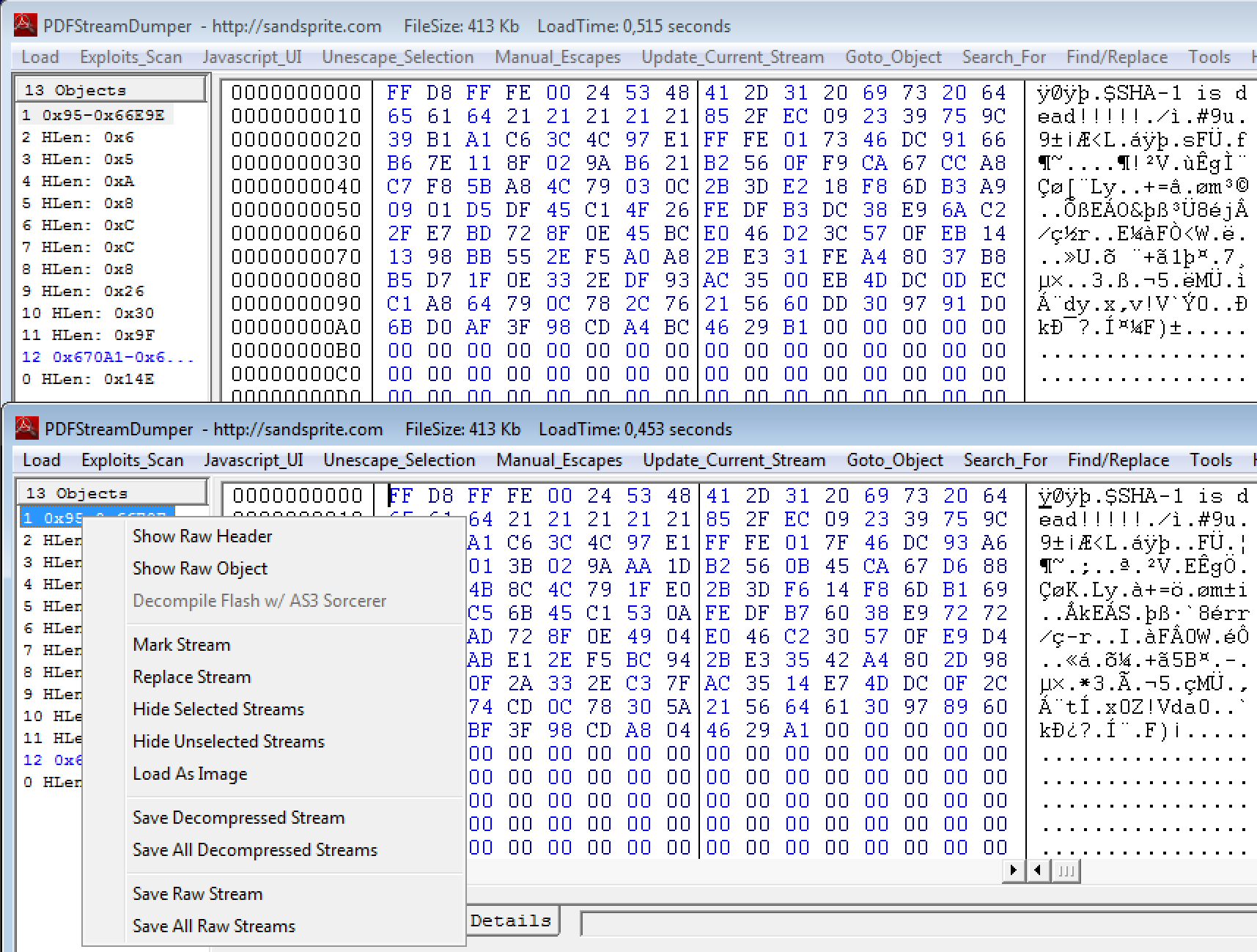
Les deux fichiers JPG contiennent les mêmes différences que les fichiers PDF.
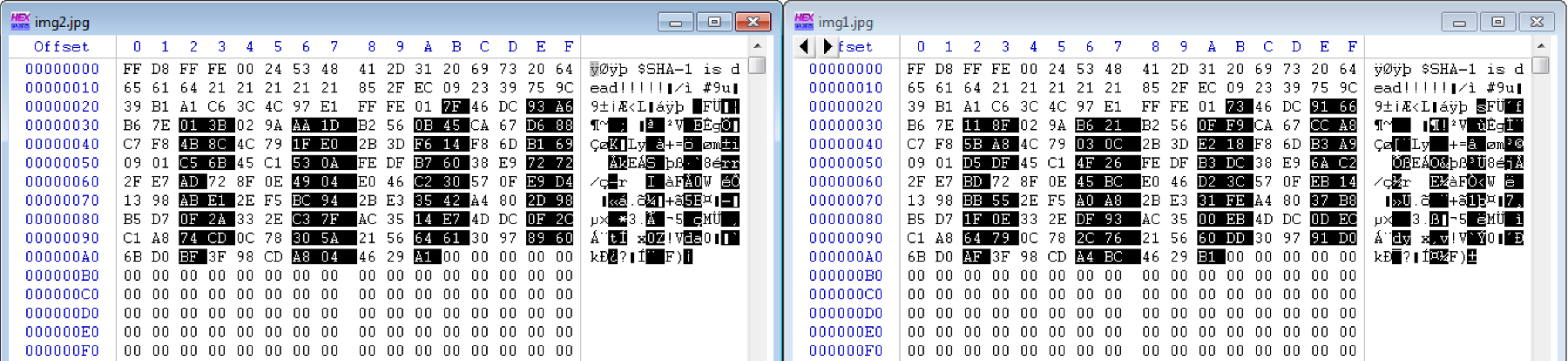
En s'intéressant à la structure les fichiers JPG, on remarque qu'ils contiennent des commentaires de tailles différentes :
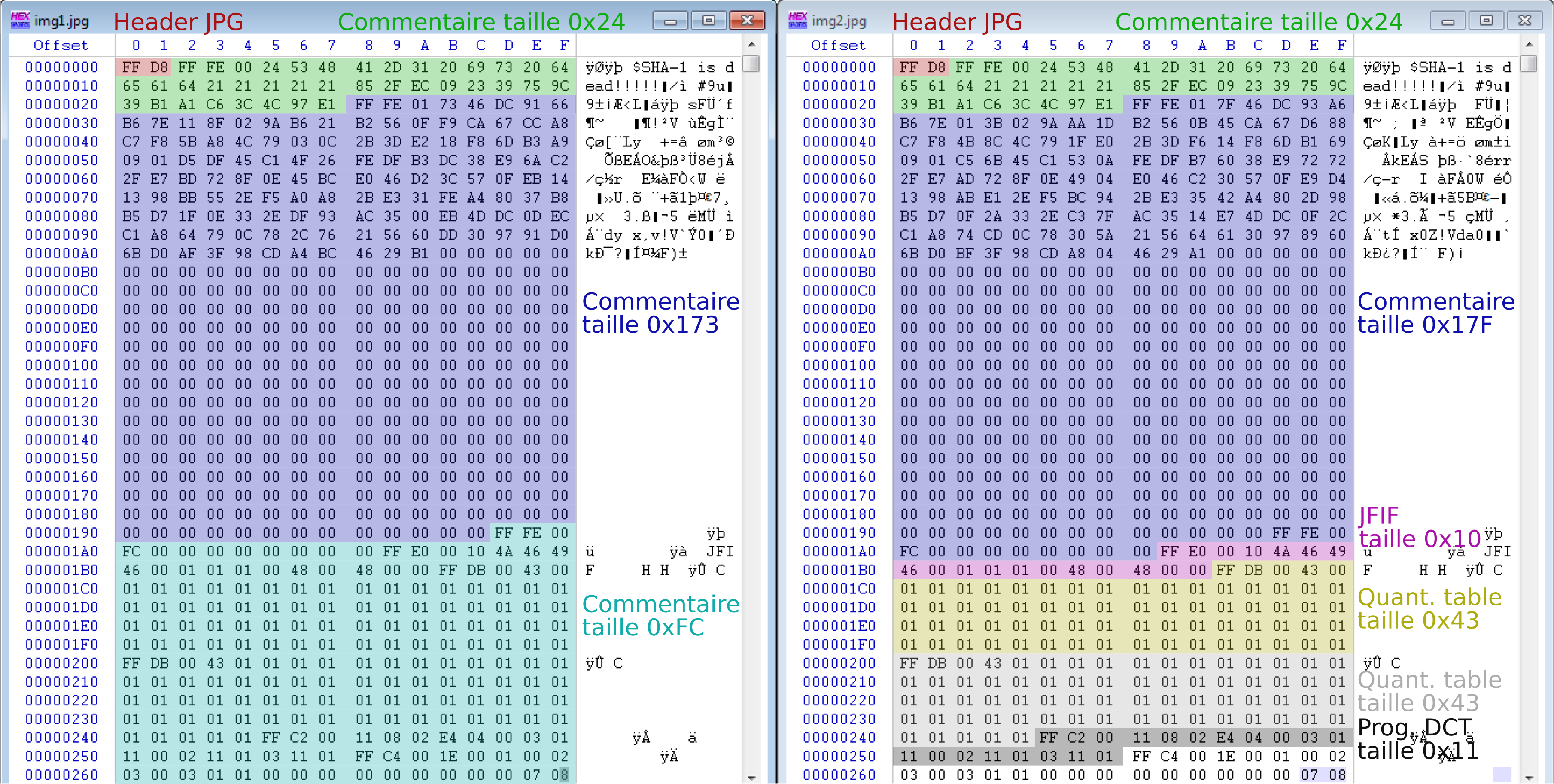
En reproduisant, sur l'intégralité des deux images, le même processus que sur l'image précédente, on obtient quelque chose comme cela :
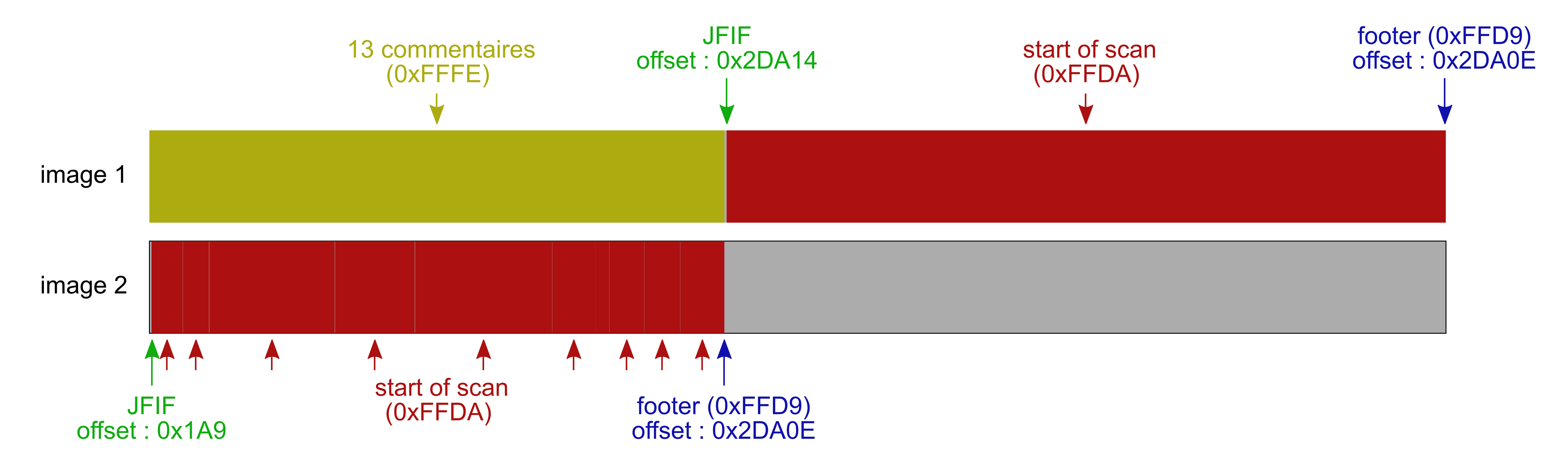
On en conclut qu'en réalité, les fichiers contiennent tous les deux les deux images.
De plus, seul l'octet à l'offset 0x2B (0x73 pour la première image et 0x7F pour la deuxième), c'est à dire le deuxième octet de la taille du deuxième commentaire, permet de passer d'une image à l'autre.
Ainsi, le logiciel en charge d'afficher les images ne lit pas les mêmes zones de données en fonction de l'octet à l'offset 0x2B. Dans le cas de l'image du premier fichier, seule la seconde moitié est réellement utile, et pour l'image du second fichier, seule la première moitié est réellement utile.
Au final, une fois que les JPG et les PDF ont été générés, les chercheurs disposaient de 369 octets pour générer leur collision. Ils n'en ont utilisé que 127, dont seulement 61 modifiés.
Pour conclure, déterminer comment cela peut fonctionner est assez simple. Mais générer la collision, c'est là qu'est la difficulté, surtout en terme de puissance de calcul.