
Suite à mon article intitulé Machine learning avec OVH prescience en quelques clics, je voulais tenter le même genre de choses avec les chiffres du MNIST. À l'époque, ça n'était pas possible. En effet, le nombre de colonnes était limité à 100. Aujourd'hui, ça n'est plus le cas, la limite étant maintenant de 1000 colonnes.
Pour rappel, les chiffres du MNIST est une base de données de chiffres écrits à la main. Comme iris, c'est un jeu de données très utilisé en apprentissage automatique. Elle regroupe 60000 images d'apprentissage et 10000 images de test, issues d'une base de données antérieure.
Pour me rapprocher d'un cas réel, je voulais travailler à partir des images plutôt qu'à partir du format de la base de données originale. On trouve les images au format png sur Internet, notamment ici. On obtient l'arborescence suivante :
|____testing
| |____0
| | |____[980 fichiers png]
| |____1
| | |____[1135 fichiers png]
| |____2
| | |____[1032 fichiers png]
| |____3
| | |____[1010 fichiers png]
| |____4
| | |____[982 fichiers png]
| |____5
| | |____[892 fichiers png]
| |____6
| | |____[958 fichiers png]
| |____7
| | |____[1028 fichiers png]
| |____8
| | |____[974 fichiers png]
| |____9
| | |____[1009 fichiers png]
|____training
|____0
| |____[5923 fichiers png]
|____1
| |____[6742 fichiers png]
|____2
| |____[5958 fichiers png]
|____3
| |____[6131 fichiers png]
|____4
| |____[5842 fichiers png]
|____5
| |____[5421 fichiers png]
|____6
| |____[5918 fichiers png]
|____7
| |____[6265 fichiers png]
|____8
| |____[5851 fichiers png]
|____9
|____[1009 fichiers png]
En partant des images, il faut trouver un moyen de transformer des png en fichiers csv. Les images font 28 pixels par 28 pixel et sont en niveau de gris. Il suffit d'enregistrer la valeur du niveau de gris des 784 pixels dans un fichier texte. Un petit script rapidement écrit en python fera l'affaire :
import os
from PIL import Image
txt = "label,"
for j in range (1,785):
txt = txt + "p" + str(j) + ","
print txt[:-1]
for i in range (0,10):
path = "./training/" + str(i)
files = os.listdir(path)
for f in files:
im = Image.open(path+ "/" + f)
txt = str(i) + ","
for p in list(im.getdata()):
txt = txt + str(p) + ","
print txt[:-1]
On l'exécute pour obtenir un fichier csv à partir duquel on pourra travailler. Il contient 60001 lignes.
$ python convert.py > num.csv
$ head -n 3 num.csv && tail -n 2 -f num.csv
label,p1,p2,p3,p4,p5,p6,p7,p8,p9,p10, [...] ,p784
0,0,0,0,0,0,0,0,0,0,0, [...] ,0
0,0,0,0,0,0,0,0,0,0,0, [...] ,0
[...]
9,0,0,0,0,0,0,0,0,0,0, [...] ,0
9,0,0,0,0,0,0,0,0,0,0, [...] ,0
On peut maintenant envoyer notre fichier sur les serveurs OVH et les faire travailler dessus.
$ # <---------- Envoi du fichier ---------->
$
$ cat parse.json
{"type":"CSV","headers":true,"separator":"comma","source_id":"num"}
$ curl -H "Authorization: Bearer xxx" -v -F input='@parse.json;type=application/json' -F input-file-1=@num.csv https://prescience-api.ai.ovh.net/ml/upload/source
* Trying 51.68.117.117...
* TCP_NODELAY set
* Connected to prescience-api.ai.ovh.net (51.68.117.117) port 443 (#0)
[...]
* SSL certificate verify ok.
> POST /ml/upload/source HTTP/1.1
> Host: prescience-api.ai.ovh.net
> User-Agent: curl/7.52.1
> Accept: */*
> Authorization: Bearer xxx
> Content-Length: 109580237
> Expect: 100-continue
> Content-Type: multipart/form-data; boundary=------------------------5eff60e8cafb6321
>
< HTTP/1.1 100 Continue
< HTTP/1.1 200 OK
< Content-Length: 659
< Content-Type: application/json
< Date: Fri, 15 Feb 2019 13:32:49 GMT
< X-IPLB-Instance: 24883
<
* Curl_http_done: called premature == 0
* Connection #0 to host prescience-api.ai.ovh.net left intact
{"uuid":"3e42c980-1957-4239-9301-828db9487257","status":"PENDING" [...]
$
$ # <---------- Vérification de l'envoi ---------->
$
$ curl -H "Authorization: Bearer xxx" https://prescience-api.ai.ovh.net/source/num
{"uuid":"75d03427-29d9-4606-8e20-349488ac38b2","status":"BUILT", [...]
$
$ # <---------- Préprocess ---------->
$
$ cat preprocess.json
{"nb_fold":10,"problem_type":"classification","multiclass":false,"label_id":"label","dataset_id":"dataset-num"}
$ curl -H "Authorization: Bearer xxx" -H "Content-Type:application/json" -X POST https://prescience-api.ai.ovh.net/ml/preprocess/num --data-binary "@preprocess.json"
{"uuid":"23d9a5a3-f20d-4f78-bc96-b5bf4c6533e5","status":"PENDING [...]
$
$ # <---------- Vérification du préprocess ---------->
$
$ curl -H "Authorization: Bearer xxx" https://prescience-api.ai.ovh.net/dataset/dataset-num
{"uuid":"067d0c99-df40-4232-97ce-c3fae196a12c", [...] "status":"BUILT" [...]
$
$ # <---------- Optimisation ---------->
$
$ cat optimize.json
{"scoring_metric": "accuracy","budget": 6}
$ curl -H "Authorization: Bearer xxx" -H "Content-Type:application/json" -X POST https://prescience-api.ai.ovh.net/ml/optimize/dataset-num --data-binary "@optimize.json"
{"uuid":"da274781-8360-4df1-8ee9-512b4f5386a4","status":"PENDING" [...]
$
$ # ~4/5h plus tard
$ # <---------- Vérification de l'optimisation ---------->
$
$ curl -H "Authorization: Bearer xxx" https://prescience-api.ai.ovh.net/optimization?dataset_id=dataset-num
{"metadata":[...] "status":"BUILT" [...]
$
$ # <---------- Récupération des évaluations ---------->
$
$ curl -H "Authorization: Bearer xxx" https://prescience-api.ai.ovh.net/evaluation-result?dataset_id=dataset-num
{"metadata":{"page_number":1,"total_pages":1,"elements_on_page":6,"elements_total":6,"elements_type":"EvaluationResult"},"content [...]
$
$ # <---------- Entrainement ---------->
$ # (uuid avec l'accuracy la plus faible)
$
$ curl -H "Authorization: Bearer xxx" -H "Content-Type:application/json" -X POST https://prescience-api.ai.ovh.net/ml/train/?model_id=num\&evaluation_uuid=f7493667-62c8-4c71-b32d-487fabd008f4
{"uuid":"91058b78-a7b8-4a64-9a2a-241a05906d86","status":"PENDING" [...]
$
$ # ~30 min plus tard
$ # <---------- Vérification du modèle ---------->
$
$ curl -H "Authorization: Bearer xxx" https://prescience-api.ai.ovh.net/model/num
{"uuid": [...] "status":"BUILT" [...]
On peut ensuite interroger le modèle avec des données contenues dans le dossier testing.
$ curl -X POST "https://prescience-serving.ai.ovh.net/eval/num/transform-model" -H "Authorization: Bearer xxx" -H "Content-Type: application/json" -d '{"arguments":{"p1":"0","p2":"0","p3":"0","p4":"0","p5":"0","p6":"0","p7":"0","p8":"0","p9":"0","p10":"0", [...] "p784":"0"}}'
[...] "result":{"label":0,"probability(0)":0.99999285,"probability(1)":8.090802E-8,"probability(2)":1.6754373E-6,"probability(3)":1.0818261E-6,"probability(4)":7.6129476E-7,"probability(5)":6.4200015E-7,"probability(6)":2.0949409E-7,"probability(7)":1.4968518E-6,"probability(8)":8.1384445E-7,"probability(9)":3.089347E-7}}
Pour valider que le système fonctionne bien, il faut tester tous les fichiers contenus dans les sous dossiers de testing. Une nouvelle fois, un petit script rapidement écrit en python fera l’affaire :
import os
import json
from PIL import Image
req = 'curl -s -X POST "https://prescience-serving.ai.ovh.net/eval/num/transform-model" '
req = req + '-H "Authorization: Bearer xxx" '
req = req + '-H "Content-Type: application/json" '
req = req + '-d '
req = req + "'"
req = req + '{"arguments":{'
for i in range (0,10):
path = "./testing/" + str(i)
files = os.listdir(path)
print "label " + str(i)
ok = 0
ok97 = 0
tot = 0
for f in files:
im = Image.open(path+ "/" + f)
j = 1
tot = tot + 1
req1 = req
for p in list(im.getdata()):
req1 = req1 + '"p'+ str(j) + '":"' + str(p) + '",'
j = j + 1
req1 = req1[:-1] + "}}'"
res = json.loads(os.popen(req1).read())
if (res['result']['label'] == i):
if (res['result']['probability('+str(i)+')'] > 0.97):
ok = ok + 1
else:
print " |__ " + f + " ~~> " + str(res['result']['label']),
print "(prob(" + str(i) + ") = " + str(res['result']['probability('+str(i)+')'])+ ")"
ok97 = ok97 + 1
else :
print " |__ " + f + " --> " + str(res['result']['label']),
print "(prob(" + str(i) + ") = " + str(res['result']['probability('+str(i)+')']),
print "/ prob(" + str(res['result']['label']) + ") =",
print str(res['result']['probability('+str(res['result']['label'])+')']) + ")"
print " ==> " + str(ok) + "+" + str(ok97) + "/" + str(tot) + " fichiers identifies correctement"
Puisque mon script n'est vraiment pas efficace, il faut attendre quelques heures pour traiter les 10000 images, mais voici (une partie) des résultats obtenus :
$ python check.py
label 0
[...]
|__ 4065.png --> 9 (prob(0) = 0.020663416 / prob(9) = 0.5178577)
|__ 4477.png (0.9034158)
|__ 3640.png (0.95766705)
|__ 9634.png --> 8 (prob(0) = 0.012318781 / prob(8) = 0.62124056)
[...]
==> 950+20/980 fichiers identifies correctement
label 1
|__ 956.png (0.5512372)
|__ 8376.png (0.65549505)
|__ 4201.png --> 7 (prob(1) = 0.1168875 / prob(7) = 0.83713335)
|__ 5457.png --> 0 (prob(1) = 0.012380271 / prob(0) = 0.44013467)
[...]
==> 1108+18/1135 fichiers identifies correctement
label 2
[...]
|__ 2462.png (0.4456795)
|__ 4205.png (0.92711586)
|__ 4615.png --> 4 (prob(2) = 0.36458197 / prob(4) = 0.6208826)
|__ 2098.png --> 0 (prob(2) = 0.42372745 / prob(0) = 0.57605886)
[...]
==> 926+80/1032 fichiers identifies correctement
label 3
|__ 7905.png (0.8120583)
|__ 63.png --> 2 (prob(3) = 0.40702614 / prob(2) = 0.58500034)
|__ 2921.png --> 2 (prob(3) = 0.050211266 / prob(2) = 0.79167867)
|__ 4808.png (0.8406261)
[...]
==> 903+85/1010 fichiers identifies correctement
label 4
|__ 610.png (0.9402425)
|__ 4438.png (0.8106081)
|__ 5068.png (0.81054324)
|__ 1178.png --> 0 (prob(4) = 0.35439998 / prob(0) = 0.42516744)
|__ 1634.png (0.8933352)
[...]
==> 887+72/982 fichiers identifies correctement
label 5
[...]
|__ 8160.png (0.89900964)
|__ 1393.png --> 7 (prob(5) = 0.2399334 / prob(7) = 0.5787523)
|__ 1378.png --> 6 (prob(5) = 0.3978061 / prob(6) = 0.42883852)
|__ 4360.png (0.6662907)
[...]
==> 783+86/892 fichiers identifies correctement
label 6
|__ 4798.png (0.7755983)
|__ 4571.png --> 8 (prob(6) = 0.028769718 / prob(8) = 0.88183796)
|__ 3550.png (0.94643056)
|__ 1569.png (0.9389341)
[...]
==> 893+44/958 fichiers identifies correctement
label 7
[...]
|__ 2507.png (0.92112225)
|__ 1754.png --> 2 (prob(7) = 0.3992076 / prob(2) = 0.5211325)
|__ 1543.png (0.96900773)
|__ 6576.png (0.64587057)
|__ 1194.png --> 9 (prob(7) = 0.47039503 / prob(9) = 0.52659583)
[...]
==> 911+91/1028 fichiers identifies correctement
label 8
|__ 9280.png (0.78978646)
|__ 2896.png --> 0 (prob(8) = 0.021465547 / prob(0) = 0.96403486)
|__ 8410.png --> 6 (prob(8) = 0.37426692 / prob(6) = 0.5977813)
|__ 6603.png (0.94607025)
[...]
==> 872+80/974 fichiers identifies correctement
label 9
[...]
|__ 1554.png (0.9546513)
|__ 1232.png --> 4 (prob(9) = 0.04343883 / prob(4) = 0.74937975)
|__ 2129.png --> 2 (prob(9) = 0.05706393 / prob(2) = 0.53022295)
|__ 9530.png (0.9462949)
[...]
==> 881+96/1009 fichiers identifies correctement
Sous forme de matrice de confusion, les choses sont plus lisibles :
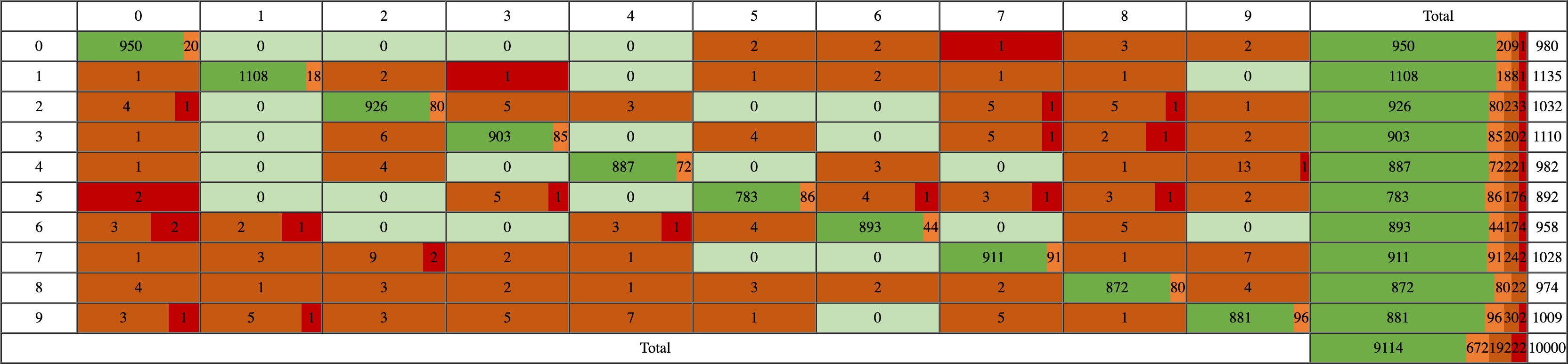
- En vert : lorsque la réponse est correcte et la probabilité supérieure à 97 %,
- En orange clair : lorsque la réponse est correcte et la probabilité inférieure à 97 %,
- En orange foncé : lorsque la réponse est incorrecte et la probabilité inférieure à 97 %,
- En rouge : lorsque la réponse est incorrecte et la probabilité supérieure à 97 %,
Ainsi, les résultats sont plutôt satisfaisants. En effet, dans près de 98 % des cas, la réponse est correcte et dans seulement 0,22 % des cas, elle est incorrecte avec une probabilité très élevée. Lorsque l'on sait que le taux d'erreur moyen d'un être humain est de l'ordre de 0,5 % à 1 % (cf. ici), on constate que la machine est au moins aussi bonne que nous, pour ne pas dire meilleure.
J'avais testé, dans l'interface web mise à disposition, le machine leaning d'OVH avec un exemple simple. Le principe est le même que l'on utilise l'interface web ou l'API et des requêtes curl, comme je l'ai fait ici. Il s'agit ici d'un exemple beaucoup plus complexe. Malgré cela, les résultats sont satisfaisants.
Encore une fois, merci OVH.